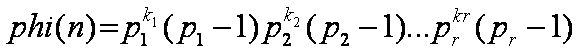引言
大数据已经是当今这个时代非常非常热的一个技术方向,所有的行业都在利用大数据提升业务,包括很多的实体行业,制造企业,都希望利用现有的数据、亦或是可以爬取的数据。挖掘出更多的商业价值。曾经我的驾校教练就和我说过一个场景,能不能利用大数据和人工智能的技术手段,来分析当地有比较大意向想要学车,考驾照,买车的人。然后把驾校的招生信息或者广告直接通过一定的渠道(短信、邮件、电话、某某贴吧、论坛、app等等方式),推送给意向准客户。我们都知道任何的技术项目,研发就是为了提升业务降低成本,特别是传统的研发,降低成本就是最最核心的目的。因为前期的:市场调研、业务产品规划、战略部署等更多的是拓展市场以及竞争对手的分析。有点扯远了。回到大数据,首先得有一个好的框架工具,那就是今天要介绍的Hadoop。同时要基于Hadoop来做大数据开发,就必须把环境给搭建起来。
CentOS虚拟机
1. VMware安装
VMware的安装就不说了,很简单下一步、下一步就好了。 下载地址:www.vmware.com/products/wo… VMware 14的版本,我用的是windows版本。
2. CentOS安装机器NAT网络配置
CentOS使用6.5的版本
-
CentOS 镜像选择
-
硬盘大小配置
-
自定义硬件配置
-
等待完成安装
-
NAT网络配置
接下来配置虚拟机的网络,点击编辑---选择“虚拟网络编辑器”
ip:192.168.241.0、 子网掩码:255.255.255.0、 网关:192.168.241.2
这些后面配置的时候都需要用到,先做一个记录
终端输入命令:
-
进入cd /etc/sysconfig/network-scripts
-
vim ifcfg-eth0
-
将ip、子网掩码、网关等信息输入并保存
-
输入/etc/init.d/network restart,重启网络服务。
-
ping www.baidu.com, 如下图表示可以访问网络。
3. 命令行神器SecureCRT的使用
直接操作VM虚拟机着实麻烦,使用SecureCRT命令行神器,连接虚拟机,可以很方便的操作。 安装好SecureCRT后,打开Session Manager-->New Session-->降master的机子的ip做为host输入,用户名是你配置的。连接的时候会要求输入密码,单机save password,方便以后连接无需再次输入密码。
4. 配置两台从节点slave机器
很简单,先挂起master主节点虚拟机,然后找到虚拟机本地磁盘的路径文件夹,复制两个文件夹并重命名如下图:
同样的,在SecureCRT中,新建两个从节点的session机器。步骤和3master的一样。
jdk的安装
jdk我用的是 1.8版本,这个可以去oracle官方下载。首先要将Windows下的文件拷贝到CentOS中,需要有一个共享文件夹。 选择电脑小图标设置,在选项的共享文件夹,启用文件共享并添加共享文件。
-
通过 cp拷贝命令将jdk1.8的压缩包拷贝到/usr/local/src/java目录下,首先创建java目录:
mkdir /usr/local/src/java
cp jdk* /usr/local/src/java
拷贝完成后,进入/usr/local/src/java通过tar -zxvf jdk*命令解压jdk的压缩包。 -
编辑配置jdk环境变量
vim ~/.bashrc
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_181
export CLASSPATH=:$CLASSPATH:$JAVA_HOME/lib
export PATH=:$PATH:$JAVA_HOME/binsource ~/.bashrc更新环境变量文件(这个文件表示当前用户组的环境变量)
-
配置从节点jdk及其环境变量
把解压的jdk文件拷贝到另外两个从节点:
- scp -rp /usr/local/src/java 192.168.241.11:/usr/local/src/
(使用scp 远程服务器拷贝命令,将java文件夹拷贝到192.168.241.11这个ip的从节点即slave1的/usr/local/src/目录下) - scp -rp /usr/local/src/java 192.168.241.12:/usr/local/src/
拷贝到slave2节点机器 - 同样修改~/.bashrc的环境配置,再通过source ~/.bashrc命令更新环境变量。如下图表示jdk环境安装成功。
- scp -rp /usr/local/src/java 192.168.241.11:/usr/local/src/
hadoop集群安装
1. hadoop安装配置
- 同样和jdk安装配置一样,将hadoop2.6.1压缩包拷贝到/usr/local/src/hadoop/目录下,并解压。
- 修改配置文件hadoop的etc目录
-
在/usr/local/src/hadoop/hadoop-2.6.1目录下新建tmp文件夹、dfs/name、dfs/data等文件夹。
-
修改配置文件:
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_152
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/java/jdk1.8.0_152
vim slaves
slave1
slave2vim core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.241.10:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/src/hadoop/hadoop-2.6.1/tmp</value> </property> </configuration> 复制代码vim hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/src/hadoop/hadoop-2.6.1/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/src/hadoop/hadoop-2.6.1/dfs/data</value> </property> <property> <name>dfs.repliction</name> <value>3</value> </property> </configuration> 复制代码vim mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> 复制代码vim yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration> 复制代码 -
将hadoop加入环境变量
vim ~/.bashrc
export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.6.1
export PATH=$PATH:$HADOOP_HOME/binsource ~/.bashrc 更新环境变量
2. 集群机器节点网络配置
将三台机器的网络配置到各自的/etc/hosts文件中。
192.168.241.10 master
192.168.241.11 slave1
192.168.241.12 slave2
同时将三台机器的域名:master、slave1、slave2配置到网络文件中
vim /etc/sysconfig/network
HOSTNAME=master
HOSTNAME=slave1
HOSTNAME=slave2
并使用hostname和bash命令然后上面域名生效,如下图:
3. 机器节点之间相互免密登录切换配置
-
关闭所有机器节点的防火墙,避免启动hadoop出现不必要的错误,难以排查问题
/etc/init.d/iptables stop
setenforce 0 -
建立机器节点间的互信免密登录
ssh-keygen
cd ~/.ssh (进入隐藏的ssh目录) -
将id_rsa.pub公钥文件中的加密字符串拷贝到authorized_keys文件中。
将其它节点机器的ssh的id_rsa.pub公钥文件中的加密字符串拷贝到authorized_keys文件中。这里我的集群有三台节点机器,那就authorized_keys文件中有三个加密字符串,如下图:
-
验证是否通过ssh互信免费登录成功
ssh slave1
4. hadoop环境运行测试
-
启动集群,初始格式化Namenode
hadoop namenode -format
./start-all.sh
-
检查集群进程是否都起来
jps命令
master
slave1
slave2
这样表示hadoop分布式集群环境搭建成功!!!